# 카프카 Pilot Project
# chatgpt has the answer to life the universe and everything (opens new window)

Answer to the Ultimate Question of Life, The Universe, and Everything from the supercomputer Deep Thought, specially built for this purpose. It takes Deep Thought 7+1⁄2 million years to compute and check the answer, which turns out to be 42
chatGpt: 사내 API를 통해 인사 정보를 전송할 때 카프카를 사용하는 것이 적절한지는 데이터 처리의 요구사항과 목적에 따라 달라집니다. 아래는 카프카를 쓸지 말지 결정하는 데 도움을 줄 수 있는 지침입니다.
카프카를 사용하는 것이 적합한 경우 : 대량의 인사 데이터가 자주 업데이트될 때
- 매일 수백~수천 명의 직원 정보(급여, 근태, 조직 변경 등)가 실시간으로 전송. 카프카는 대규모 데이터 처리와 고성능 전송에 강합니다. 여러 시스템에 동시에 데이터 전달이 필요할 때
- 인사 시스템의 데이터가 급여 시스템, 조직도 시스템, ERP에 동시에 전송돼야 하는 경우. Publisher-Subscriber 구조로 하나의 소스에서 여러 소비자에게 데이터를 동시 전달 가능. 비동기 처리와 장애 복원력이 중요할 때
- 급여 데이터가 전송 중 문제가 생겨도 재시도나 복원이 필요할 때. 카프카는 메시지 내구성이 높아, 장애가 발생해도 데이터를 손실 없이 보관하고 복구할 수 있습니다. 데이터 파이프라인 구축을 고려할 때
- 인사 데이터를 실시간 분석하거나 모니터링할 필요가 있을 때. 카프카를 사용하면 Spark/Flink 등과 연계해 실시간 분석 파이프라인을 쉽게 구성할 수 있습니다.
카프카가 적합하지 않은 경우 : 단순한 데이터 조회 및 동기식 API 호출
- 조직 정보가 필요할 때 HR 시스템에서 API로 즉시 호출. 카프카는 비동기 처리에 특화되어 있어, 실시간 조회가 필요한 동기식 호출에는 부적합합니다. 데이터 전송 빈도가 낮고 복잡하지 않은 경우
- 월 1~2회만 인사 정보가 업데이트되고, 소수의 시스템만 사용. 카프카는 구축 및 운영 비용이 높기 때문에, 단순한 API 호출이 더 효율적일 수 있습니다. 보안과 데이터 정합성이 매우 중요한 경우
- 민감한 인사 정보(급여, 개인정보 등)를 전송할 때, 데이터 정합성이 100% 보장돼야 한다면 동기 API가 더 적합합니다. 카프카는 메시지 전송이 비동기 방식이라 정합성 보장이 어려울 수 있습니다.
결론 및 추천
단순한 전송 및 조회가 필요하다면: RESTful API나 gRPC 같은 동기식 통신을 사용하는 것이 더 간단하고 적합합니다. 여러 시스템에 데이터를 비동기로 전송하거나 대용량 처리/실시간 처리가 필요하다면 카프카가 유용합니다. 만약 양쪽 요구사항이 모두 존재한다면 다음과 같은 혼합 방식을 고려해보세요:
주요 동기식 API로 정합성을 보장하면서, 비동기 스트림 처리가 필요한 일부 데이터는 카프카를 활용해 전달합니다. 카프카의 필요성은 전송 빈도, 데이터 처리 요구 사항, 장애 복구 필요성에 따라 결정되므로 프로젝트의 특성을 잘 고려하는 것이 좋습니다.
# 요구사항
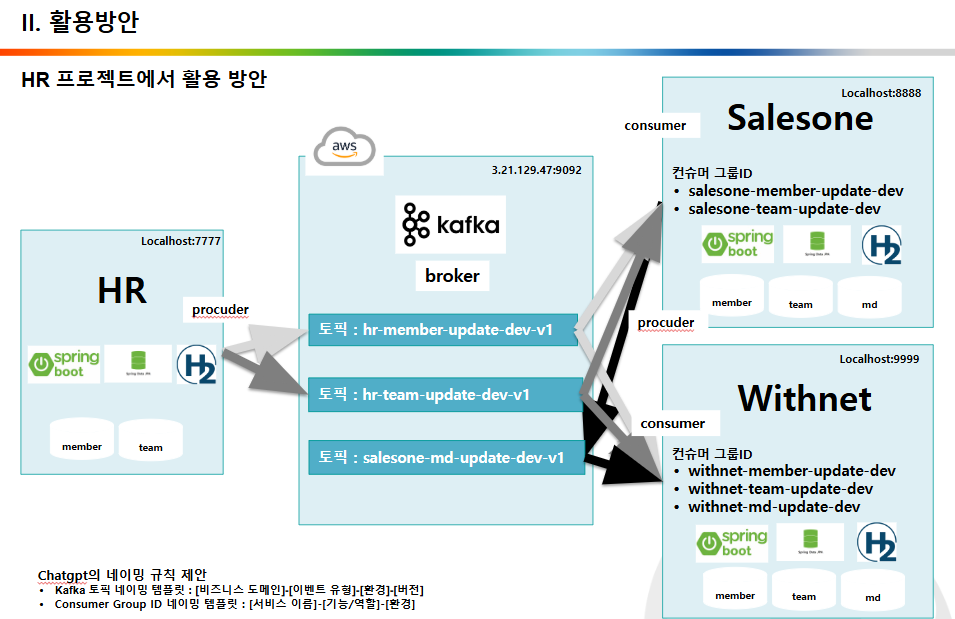
- 두 회사의 인사정보 통합
- 여러 시스템으로 대량의 인사정보 주기적 전파
- 여러 시스템 인사/시스템 권한 정보 실시간 전파
# 시연 설명
# 시나리오
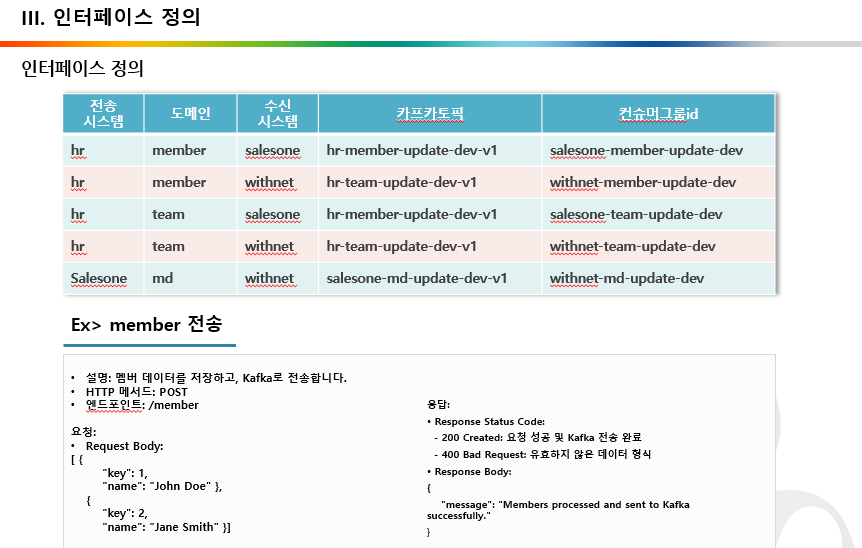
- 인사정보 10000건 각 시스템 전파
- 팀 정보 10000건 각 시스템 전파
- md 정보 시스템 전파
# 기술스택
- spring boot + jpa + h2 로컬 3대
- aws kafka 1대