# 카프카 커맨드라인 툴
# 호스트 설정
sudo vi /etc/hosts
3.21.129.47 my-kafka
2
# kafka-topics.sh
- 토픽 : 카프카에서 데이터를 구성하는 가장 기본 개념. RDBMS의 테이블과 유사하다고 볼 수 있다. 토픽은 카프카 컨슈머 또는 프로듀서가 카프카 브로커에 생성되지 않은 토픽에 대해 데이터를 요청할때, 혹은 커맨드 라인 툴로 명시적으로 토픽을 생성할 수 있다. 토픽을 효과적으로 유지보수 하기 위해서는 토픽을 명시적으로 생성하는 것을 추천.
# 토픽 생성
로컬
bin/kafka-topics.sh --create --bootstrap-server 3.21.129.47:9092 --topic hello.kafka
bin/kafka-topics.sh \
--create \ # 토픽 생성 명령어
--bootstrap-server my-kafka:9092 \ # 토픽을 생성할 카프카 클러스터를 구성하는 브로커들의 ip 와 port
--partitions 3 \ # 파티션 개수
--replication-factor 1 \ # 파티션 복제할 복제 개수
--config retention.ms=172800000 \ # 추가 설정 (데이터 유지 기간, 172800000은 2일이다.)
--topic hello.kafka.2 # 토픽 이름
2
3
4
5
6
7
8
9
10

# 토픽 리스트 조회
bin/kafka-topics.sh --bootstrap-server my-kafka:9092 --list
# 토픽 상세조회
bin/kafka-topics.sh --bootstrap-server my-kafka:9092 --describe --topic hello.kafka.2

# 토픽 옵션 수정
# 파티션 개수 변경
bin/kafka-topics.sh --bootstrap-server my-kafka:9092 \
--topic hello.kafka \
--alter \
--partitions 4
# 파티션 확인
bin/kafka-topics.sh --bootstrap-server my-kafka:9092 \
--topic hello.kafka \
--describe
# retention 설정. --add-config:이미 존재하는 설정값은 변경, 존재하지 않는 설정값은 신규
bin/kafka-configs.sh --bootstrap-server my-kafka:9092 \
--entity-type topics \
--entity-name hello.kafka \
--alter --add-config retention.ms=86400000
# retention 확인
bin/kafka-configs.sh --bootstrap-server my-kafka:9092 \
--entity-type topics \
--entity-name hello.kafka --describe
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# kafka-console-producer.sh
kafka-console-producer.sh 로 생성된 hello.kafka 토픽에 데이터를 넣을 수 있다
토픽에 넣는 데이터는 레코드(record) 라고 부르며 메시지 키(key)와 메시지 값(value)으로 이루어져 있다.
메시지 키 없이 값만 보내기. 키는 자바의 null로 기본 설정되어 브로커로 전송된다.
bin/kafka-console-producer.sh --bootstrap-server my-kafka:9092 --topic hello.kafka
> hello
> kafka
> 0
> 1
> 2
> 3
2
3
4
5
6
7
메시지 키를 가지는 레코드 보내기
bin/kafka-console-producer.sh --bootstrap-server my-kafka:9092 \
--topic hello.kafka \
--property "parse.key=true" \
--property "key.separator=:"
>key1:no1
>key2:no2
>key3:no3
2
3
4
5
6
7
구분자를 설정하지 않으면 기본 설정은 tab delimiter(/t) 이다
메시지 키와 메시지 값을 함께 전송한 레코드는 토픽의 파티션에 저장된다. 메시지 키가 존재하는 경우에는 키의 해시값을 작성하여 존재하는 파티션중 한개에 할당된다. 메시지 키가 동일한 경우에는 동일한 파티션으로 전송된다.
# kafka-console-consumer.sh
데이터 확인
bin/kafka-console-consumer.sh --bootstrap-server my-kafka:9092 \
> --topic hello.kafka \
> --from-beginning
2
3
키와 값 확인
bin/kafka-console-consumer.sh --bootstrap-server my-kafka:9092 \
> --topic hello.kafka \
> --property print.key=true \
> --property key.separator="-" \
> --group hello-group \ # 컨슈머 그룹 생성
> --from-beginning
2
3
4
5
6
--group 옵션을 통해 신규 컨슈머 그룹을 생성했다. 컨슈머 그룹을 통해 가져간 토픽의 메시지는 가져간 메시지에 대해 커밋(commit)한다. 커밋이란 컨슈머가 특정 레코드까지 처리를 완료했다고 레코드의 오프셋 번호를 카프카 브로커에 저장하는 것이다. 커밋 정보는 __consumer_offsets 이름의 내부 토픽에 저장된다.

# kafka-consumer-group.sh
컨슈머 그룹은 컨슈머를 동작할 때 컨슈머 그룹 이름을 지정하면 새로 생성된다.
# 컨슈머 그룹의 리스트 확인
bin/kafka-consumer-groups.sh --bootstrap-server my-kafka:9092 --list
# 컨슈머 그룹 상세 조회
bin/kafka-consumer-groups.sh --bootstrap-server my-kafka:9092 \
> --group hello-group \
> --describe
2
3
4
5
6
7
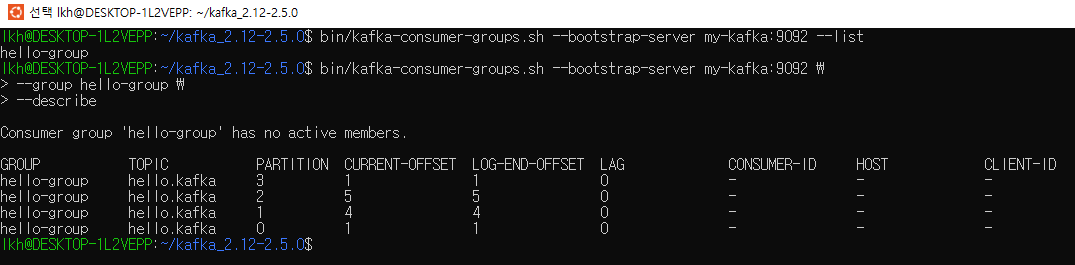
- GROUP, TOPIC, PARTITION : 조회한 컨슈머 그룹이 마지막으로 커밋한 토픽과 파티션을 나타낸다.
- CURRENT-OFFSET : 컨슈머 그룹이 가져간 토픽의 파티션에 가장 최신 오프셋(offset)이 몇 번인지 나타낸다. 오프셋이란 파티션의 각 레코드에 할당된 번호다. 이 번호는 데이터가 파티션에 들어올 때 마다 1씩 증가한다
- LOG-END-OFFSET : 해당 컨슈머 그룹의 컨슈머가 어느 오프셋까지 커밋했는지 알 수 있다.
- LAG : 컨슈머 그룹이 토픽의 파티션에 있는 데이터를 가져가는데에 얼마나 지연이 발생하는지 나타내는 지표.
# kafka-verifiable-producer, consumer.sh
string 타입 메시지 값ㅇ르 코드 없이 주고받을 수 있다. 간단한 네트워크 통신 테스트
bin/kafka-verifiable-producer.sh --bootstrap-server my-kafka:9092 \
> --max-messages 10 \
> --topic verify-test
2
3
전송한 데이터는 kafka-verifiable-consumer.sh로 확인 가능
bin/kafka-verifiable-consumer.sh --bootstrap-server my-kafka:9092 \
--topic verify-test \
--group-id test-group
2
3
# kafka-delete-records.sh
test 토픽의 0번 파티션에 저장된 데이터중 0 부터 30 오프셋 데이터까지 지우기
sudo vi delete-topic.json
{"partitions":[{"topic":"test","partition":0,"offset":50}],"version":1}
bin/kafka-delete-records.sh --bootstrap-server my-kafka:9092 --offset-json-file delete-topic.json
2
3
4
5
토픽의 특정 레코드 하나만 삭제되는 것이 아니라 파티션에 존재하는 가장 오래된 오프셋부터 지정한 오프셋까지 삭제된다. 카프카에서는 토픽의 파티션에 저장된 특정 데이터만 삭제할 수 없다.
# kafka shutdown
The Cluster ID xSMQ1fl_S6ynL-7pnLjXWQ doesn't match stored clusterId Some(vGNsOSo9S56TtQegyLvtNA) in meta.properties. The broker is trying to join the wrong cluster. Configured zookeeper.connect may be wrong.
# Kafka 데이터 디렉터리 초기화
sudo rm -rf /tmp/kafka-logs
2
# 누구냐 넌
[2024-11-26 00:16:26,032] WARN [SocketServer brokerId=0] Unexpected error from /205.210.31.152; closing connection (org.apache.kafka.common.network.Selector)
org.apache.kafka.common.network.InvalidReceiveException: Invalid receive (size = 1195725856 larger than 104857600)
at org.apache.kafka.common.network.NetworkReceive.readFrom(NetworkReceive.java:105)
at org.apache.kafka.common.network.KafkaChannel.receive(KafkaChannel.java:448)
at org.apache.kafka.common.network.KafkaChannel.read(KafkaChannel.java:398)
at org.apache.kafka.common.network.Selector.attemptRead(Selector.java:678)
at org.apache.kafka.common.network.Selector.pollSelectionKeys(Selector.java:580)
at org.apache.kafka.common.network.Selector.poll(Selector.java:485)
at kafka.network.Processor.poll(SocketServer.scala:861)
at kafka.network.Processor.run(SocketServer.scala:760)
at java.lang.Thread.run(Thread.java:750)
2
3
4
5
6
7
8
9
10
11