# [ORACLE] 실행계획 보기
# PLAN 보는법
- 위에서 아래로 내려가면서 제일 먼저 읽을 위치 찾기
- 내려가는 과정에서 같은 들여쓰기가 있으면, 무조건 위에서 아래 순으로 읽기
- 같은 레벨에 들여쓰기된 하위 스텝이 존재하면, 가장 안쪽으로 들여쓰기 된 스텝을 시작으로 상위 스텝으로 읽기
# PLAN 용어
PLAN에 보이는 용어에 대한 의미 입니다.
- Cost
- 쿼리를 수행함에 있어 사용된 자원이나, 작업의 단위를 나타냅니다. 적을 수록 쿼리가 더 효율적이겠죠
- 단, 어쩔수 없이 Full Scan을 해야 하는 쿼리는 의미가 없을 수도 있습니다.
- Cardinality
- 행 집합에서 행의 수를 표시 합니다. 행 집합은 기본 테이블, 뷰, 조인이나, GROUP BY의 결과 입니다.
- 행 집합을 의미하니 적게 나타날수록 SQL이 빠를 수 있습니다.
# dbeaver 실행계획 보기
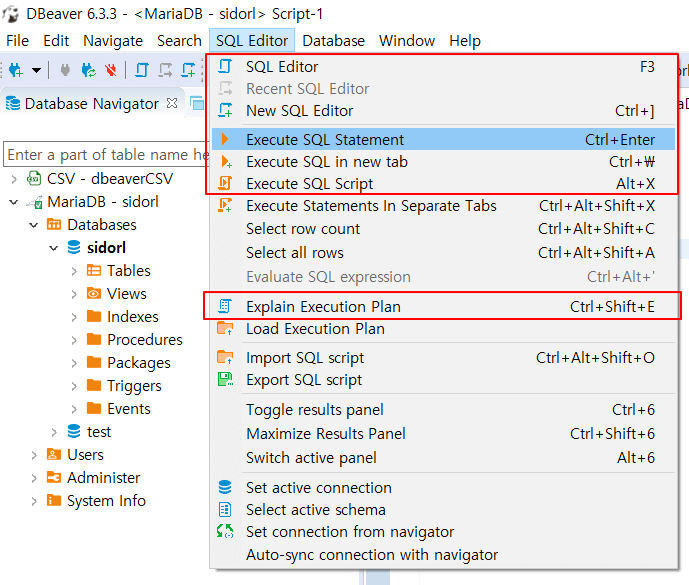
https://sidorl.tistory.com/31 (opens new window)
# EXPLAIN plan FOR
EXPLAIN plan FOR
SELECT ename, sal, job
FROM emp
WHERE sal = 3000;
SELECT *
FROM TABLE(dbms_xplan.display);
2
3
4
5
6
7
# DBMS_XPLAN.DISPLAY 출력 이해

- Id : 실행계획에서의 구분자
- Operation : 각 단계에서의 어떤 작업이 일어났는지 표시
- Name : 테이블명이나 index 명을 표시함
- Rows : 해당 쿼리 계획 단계에서 나올 것으로 예상되는 행의 수
- Byte : 실행 계획의 각 단계가 반환할 것으로 예상 되는 데이터의 크기를 바이트로 나타낸 수. 이 수는 행의 수와 행의 예상 길이에 따라 결정됨
- Cost : CBO가 쿼리 계획의 각 단계에 할당한 비용. CBO는 동일한 쿼리에 대해 다양한 실행 경로/계획을 생성하며 모든 쿼리에 대해 비용을 할당함 위의 실행 계획에선 전체 비용이 13인것을 알수 있음
- Time: 각 단계별 수행 시간
# 실행계획 초기화
db 이관 작업후 특정 테이블 포함 쿼리 수행 속도가 느려 원인을 파악해 보니 pk가 누락이 되었었다. (어떻게 그럴수가 있지.. pk 누락된지 모르고 튜닝 요청을 추가로 계속 올렸었따 =3= ) pk 생성후에도 옵티마이저가 계속 이전 실행계획으로 수행한다면 dba에게 실행 계획 초기화를 요청하자.
# SCAN 의 종류와 속도
SCAN이란, 데이터를 읽는 작업을 말하는데 SCAN을 수행하는 방식을 일컬어 접근 경로라고 합니다.
- FULL TABLE SCAN : 테이블의 전체 데이터를 읽어 조건에 맞는 데이터를 추출하는 방식
- ROWID SCAN : ROWID를 기준으로 데이터를 추출하며 단일 행에 접근하는 방식 중에서 가장 빠름
- INDEX SCAN : 말 그대로 인덱스를 활용하여 원하는 데이터를 추출하는 방식
https://goldswan.tistory.com/33 (opens new window)
[INDEX UNIQUE SCAN]
인덱스에 존재하는 PK(기본키) 또는 Unique Index처럼 유일한 값을 스캔할 때 발생합니다.
select empno from emp where empno = 7369;--PK 조회
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 0 (0)| 00:00:01 |
|* 1 | INDEX UNIQUE SCAN| PK_EMP | 1 | 4 | 0 (0)| 00:00:01 |
----------------------------------------------------------------------------
2
3
4
5
6
[TABLE ACCESS (BY INDEX ROWID)]
인덱스에 존재하지 않는 값을 인덱스를 경유하여 조회할 때 발생합니다.(테이블 랜덤 액세스)
select empno, ename --인덱스에 존재하지 않는 ename 조회
from emp
where empno = 7369;
2
3
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 10 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
2
3
4
5
6
7
[INDEX RANGE SCAN]
인덱스를 비교 연산자(>, >=, <, <=, like, between 등)를 사용하여 범위 탐색하거나 Unique Index가 아닌 인덱스를 탐색할 경우 발생합니다.
비교 연산자로 스캔
select empno
from emp
where empno >= 7500;--비교연산자 조회
2
3
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 10 | 40 | 1 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| PK_EMP | 10 | 40 | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------
2
3
4
5
6
Unique Index가 아닌 인덱스로 스캔
create index emp_idx1 on emp(deptno, empno);--Unique Index가 아닌 인덱스
select deptno, empno from emp where deptno = 10 and empno = 7521;
2
3
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 7 | 1 (0)| 00:00:01 |
|* 1 | INDEX RANGE SCAN| EMP_IDX1 | 1 | 7 | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------
2
3
4
5
6
[INDEX SKIP SCAN]
복합 인덱스의 선행 컬럼에 대한 조건이 없고 후행 컬럼만 있을 경우 발생합니다. 인덱스 선두 컬럼의 Distinct Value 개수가 적고 (중복이 많음) 후행 컬럼의 Distinct Value 개수가 많을 때 (중복이 적음) 유용합니다. (9i 버전부터 사용 가능)
create index emp_idx2 on emp(deptno, ename);
select deptno, ename from emp where ename like 'J'||'%';--후행 컬럼으로 조회
2
3
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 9 | 1 (0)| 00:00:01 |
|* 1 | INDEX SKIP SCAN | EMP_IDX2 | 1 | 9 | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------
2
3
4
5
6
[INDEX FULL SCAN]
조건절에서 인덱스 칼럼을 하나 이상 사용하는 경우 또는 조회 칼럼들이 하나의 인덱스에 모두 존재할 경우 발생합니다. 인덱스 구성 칼럼은 최소 한 개의 컬럼은 NOT NULL 제약조건을 충족해야 합니다. TABLE FUll SCAN 보다 I/O 비용을 줄일 수 있거나 정렬 결과를 쉽게 얻을 수 있을 경우 INDEX FULL SCAN을 선택합니다.
select empno, deptno from emp;
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 12 | 84 | 1 (0)| 00:00:01 |
| 1 | INDEX FULL SCAN | EMP_IDX1 | 12 | 84 | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------
2
3
4
5
6
[INDEX FAST FULL SCAN]
SELECT절과 조건절에 사용한 모든 칼럼이 인덱스 칼럼으로 구성되어 테이블을 검색하지 않고 인덱스만 검색하여 원하는 데이터를 얻을 수 있는 경우 사용하는 방식입니다. 인덱스 트리 구조를 무시하고 인덱스 세그먼트 자체를 Multiblock I/O 방식으로 스캔하므로 Singleblock I/O 방식인 INDEX FULL SCAN보다 빠릅니다. 병렬 처리가 가능하나 순서는 보장하지 않습니다.
select /*+ index_ffs(emp emp_idx1) */ deptno, empno from emp;
---------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 12 | 84 | 2 (0)| 00:00:01 |
| 1 | INDEX FAST FULL SCAN| EMP_IDX1 | 12 | 84 | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------------
2
3
4
5
6
[TABLE ACCESS FULL]
테이블을 인덱스를 경유하지 않고 스캔할 때 발생합니다. 인덱스 손익 분기점을 넘을 때 인덱스 스캔보다 FULL 스캔이 유리합니다. (대용량 데이터 조회와 같이 인덱스로 스캔하여 테이블 랜덤 액세스가 많이 발생할 경우 FULL 스캔이 더 유리할 수 있습니다. )
select /*+ full(emp) */ * from emp;
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 12 | 468 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| EMP | 12 | 468 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------
2
3
4
5
6